Using unsafe tricks to examine Rust data structure layout
Introduction
[Edit (20/9/2016)] Please check this Reddit discussion where some readers have pointed out errors
Whether you are learning Rust or C, it is important that you have an understanding of how various data types are represented in memory. For example, when learning C, if you are not able to sketch on a piece of paper how the array ‘a’ is represented in memory, you will have a hard time understanding the meaning of expressions like *a, **a etc (array decaying rules make this tricky in C):
main()
{
char *a[] = {"abc", "def", "ijk"};
}
In C, it is possible to learn more about the representation of the array simply by printing out the value of various expressions involving ‘a’. One can also think of using ‘gdb’ to peek into memory. Finally, it is not too difficult to read and understand the assembly code generated by the C compiler.
Things are not that easy in Rust. References in Rust are not the free spirits you encounter in the land of C - they have a lot of restrictions imposed on them (for an excellent reason, the safe execution of your code). But these restrictions will have to be lifted if you wish to write very low level Rust code (say operating system kernels, embedded systems) - Rust does indeed provide an ‘unsafe’ mechanism using which you are free to do all the wild and crazy things you can do with pointers in C. Needless to say:
this should be used with extreme caution if you do not wish your Rust code to blow up the way your C code sometimes does! Unless you are writing very low level code, you will seldom have the need to use ‘unsafe’.
In this article, we will use the ‘unsafe’ mechanism in Rust purely for educational purpose - to understand how Rust lays out objects of different types in memory.
Getting the address of a variable
If you expect the following program to print the address of ‘a’, you are in for surprise:
fn main() {
let a = 10;
let b = &a;
println!("{:?}, {:?}", b, b+1);
}
You will see the value of ‘a’ and ‘a+1’ (that is, 10 and 11) in the output.
Even though ‘b’ contains address of ‘a’, when you try to access ‘b’, Rust will automatically derefer the pointer and give you the pointed-to value (ie, Rust will automatically do *b when you make use of ‘b’ in an expression like ‘b+1’ - we need not write *b explicitly).
This behaviour is very convenient because that is what you really want to do with a pointer: access the pointed-to object.
It is also safe; if you are able to perform arithmetic on the memory address and then derefer the modified address (say do something like *(b+1)), there is no guarantee that the modified address (b+1) is pointing to a valid memory location.
But what if you really want to see the address of ‘a’?
fn main() {
let a = 10;
let b = &a;
println!("{:?}", b as *const i32);
}
This is the output I got on my system (x86_64 Linux):
0x7ffeebf83a24
[Edit(14/09/2016)] You can use
println!("{:p}", &a)
to see the address of ‘a’. Thanks Manish for pointing this out!
Rust has a “raw pointer” type, written as “* const T” (where T is some type like say i32). None of the safety checks associated with ordinary Rust references are applicable to raw pointers. In the above example, we are asking Rust to interpret ‘b’ as a raw pointer, which will let us see the actual address stored in ‘b’.
Here is another way to write the same program:
fn main() {
let a = 10;
let b: *const i32 = &a as *const i32;
println!("{:?}", b);
}
The explicit declaration of the type of ‘b’:
let b: *const i32 = &a as *const i32;
is not really required as Rust can easily infer the type; we need to only write:
let b = &a as *const i32;
Dereferencing raw pointers
Here is a fun program in C:
int main()
{
int *p = 0;
int k = *p;
}
This will of course give you a segfault as you are trying to derefer the null pointer.
Let’s try to write an equivalent one in Rust:
fn main() {
let p = 0 as *const i32;
}
This will compile and run without any problem; you can store 0 in a raw pointer.
Now let’s try this one:
fn main() {
let p = 0 as *const i32;
let k = *p;
}
We are now trying to access the memory location whose address is 0; you will find that the code will not compile. We get an error which says:
a5.rs:3:13: 3:15 error: dereference of raw pointer requires
unsafe function or block [E0133]
a5.rs:3 let k = *p;
Rust does not allow us to derefer raw pointers because it is a dangerous operation with the potential for undefined behaviours; a raw pointer is not guaranteed to contain valid memory addresses.
If you are really stubborn, Rust will let you do this:
fn main() {
let p = 0 as *const i32;
unsafe {
let k = *p;
}
}
The above program will compile properly; and you get a wonderful segfault when you run it!
Any code which derefers a raw pointer should be explicitly marked as “unsafe”; the big promise of Rust is memory safety without using a garbage collector - you don’t get that safety in unsafe blocks.
Why does Rust need unsafe?
Say you are writing code which runs on a microcontroller. Your code needs to write some data to an I/O port. Most often, I/O ports are memory mapped, that is, you can access the I/O port by reading from or writing to specific memory locations. If you have an I/O port which is mapped to address 0x7134af23 and you want to write 1 byte of data:
int main()
{
unsigned char *c = (unsigned char*)0x7134af23;
*c = 'A';
}
Unless you have raw pointers and “unsafe” blocks, Rust code will not be able to do low level manipulations like this which are essential for writing operating systems and embedded systems code. Rust is targeted to be a replacement for C, so it should be capable of doing everything that is possible in C. As the dangerous parts of the code are explicitly marked as “unsafe”, it becomes easy to identify and more thoroughly audit such blocks of code. Redox OS, an operating system written in Rust, has demonstrated that it is possible to write a large percentage of the kernel code in safe rust.
Looking at the memory layout of 32 bit integers
Here is a C program which declares a 32 bit integer and tries to read it back as four independent bytes:
#include <stdint.h>
#include <stdio.h>
int main()
{
uint32_t a = 0x12345678;
uint8_t *b = (uint8_t*)&a;
printf("%x, %x\n", *b, *(b+1));
printf("%x, %x\n", *(b+2), *(b+3));
}
If you run the code on a little endian system, you will get 0x78, 0x56, 0x34 and 0x12.
Here is how you can do the same in Rust:
fn print_bytes(p: &u32) {
let q = p as *const u32;
let r = q as u64;
for i in 0..4 {
unsafe {
print!("{:x}, ", *((r + i) as *const u8));
}
}
println!("");
}
fn main() {
let a:u32 = 0x12345678;
print_bytes(&a);
}
Here are some points to be noted:
- It is not possible to cast a &u32 as *const u8
- You can cast a *const u32 as *const u8
- You can’t do addition on a raw pointer
- We have 64 bit addresses, so we need a u64 to store an address
- It is possible to cast a u64 as a raw pointer
Using the “transmute” function
It is possible to get the same effect using “transmute”:
use std::mem;
fn main() {
let a:u32 = 0x12345678;
let b:[u8; 4];
b = unsafe{mem::transmute(a)};
println!("{:x},{:x},{:x},{:x}", b[0],b[1],b[2],b[3]);
}
The “transmute” function takes in an object of type u32 and returns a view of that object as an array of four 8 bit values, which gets copied to b. You can think of it as a kind of copy operation which copies all the bits of an object of type T1 to an object of type T2. Both T1 and T2 must have the same size and alignment.
Warning: Use of the “transmute” function is discouraged. As Rust beginners, most of us will have absolutely no need for this operation in the code that we write. I am using it here purely for educational purpose.
Understanding Vector Layout
The figure below shows how a vector is mapped to memory; we have a triplet of values: (pointer,capacity,length) on the stack. The space for the contents of the vector is allocated on the heap. The “length” attribute specifies the actual number of elements in the vector, “capacity” represents the actual amount of space allocated (which may be larger than the number of elements in the vector) on the heap and “pointer” points to the heap location where the contents of the vector are stored.
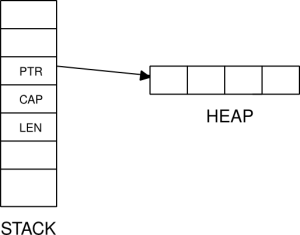
Here is a program which reads the stack locations representing a vector and converts the data into three u64 values:
use std::mem;
fn main() {
let p:[u64;3];
let mut v:Vec<i32> = vec![];
v.push(10);
println!("{:?}", &v[0] as *const i32);
p = unsafe {mem::transmute(v)};
println!("{:x}, {:x}, {:x}",p[0], p[1], p[2]);
}
Here is the output I got on my machine:
0x7f32bea1d000
7f32bea1d000, 4, 1
The heap allocated block starts at 0x7f32bea1d000, the vector has enough space to store 4 elements even though only one element is actually stored.
And now a small trick; let’s change the stack representation of a vector within an unsafe block:
use std::mem;
fn main() {
let p:[u64;3] = [0, 1, 1];
let mut v:Vec<i32> = vec![];
v = unsafe {mem::transmute(p)};
println!("{:?}", v[0]);
}
The program changes the stack representation of the vector; the pointer value is now 0 and capacity and length are both 1. The program will segfault when you try to print v[0] because it will try to derefer 0.
Once again: these are horrible tricks which shouldn’t be employed in production code!
Exercise: You can write a program to understand how Strings are represented in memory.
The transmute operation requires that you know the exact size of the object to be transmuted. Here is how you can find out the size of a Rust data type:
use std::mem;
fn main() {
let v:Vec<i32> = vec![1,2,3,4,5];
println!("{:?}", mem::size_of::<Vec<i32>>());
}
I got 24 (bytes) on my machine (Linux, x86_64). You can think of this as three 8 byte values.
Representing slices in memory
A slice is just a pair of values stored on the stack; a pointer to some element of an array and a length.
Here is a program which prints out the stack representation of a slice:
use std::mem;
fn main() {
let v:[i32; 8] = [1,2,3,4,5,6,7,8];
let t = &v[3..7];
let r:[u64;2];
println!("{:?}", &v[3] as *const i32);
r = unsafe {mem::transmute(t)};
println!("{:x}, {:x}", r[0], r[1]);
}
Here is what I got on my machine:
0x7ffcb9b46284
7ffcb9b46284, 4
It is evident that the slice has length 4 and that it is pointing to the element at index 3 in the array.
Representing sum types
Let’s first find out the size of a simple enum:
use std::mem;
enum Color {
Red,
Green,
Blue,
}
fn main() {
println!("{}", mem::size_of::<Color>());
}
The program gives 1 as the output on my machine. So we shall assume that Red, Green and Blue are encoded simply as numbers 0, 1 and 2. Let’s check:
use std::mem;
enum Color {
Red,
Green,
Blue,
}
fn main() {
let c = Color::Blue;
let d:u8;
d = unsafe {mem::transmute(c)};
println!("{}", d);
}
I am getting the output 2 when I run this on my system.
What if your sum type is more complex, like this:
enum Color {
Red(u32),
Green(u32),
Blue(u32),
}
Let’s find out the size of this enum.
use std::mem;
enum Color {
Red(u32),
Green(u32),
Blue(u32),
}
fn main() {
println!("{}", mem::size_of::<Color>());
}
I am getting 8 as the output.
A variable of type Color can assume only one of 3 possible values at any point in time. Each value needs 4 bytes of storage, but because you are storing only one value at any point in time, the compiler allocates only 4 bytes instead of 12.
But now there is a problem. How does Rust represent the fact that what is stored in this common 4 byte storage area is a “Red”. Or, a “Green”, or a “Blue”? It will be impossible to execute “match” operations without this knowledge.
The solution is simple. Allocate another 4 byte location as a “tag”. If the tag value is 0, the next 4 byte location represents a Red, if the tag is 1, it is a Green and so on … (only 1 byte of the tag space will be used, the other 3 bytes are most probably used as a padding to meet the alignment restriction for the 32 bit integer Red/Green/Blue data field which comes next).
Let us write another program to find out.
use std::mem;
enum Color {
Red(u32),
Green(u32),
Blue(u32),
}
fn main() {
let c = Color::Green(0x12);
let d:[u32;2];
d = unsafe {mem::transmute(c)};
println!("{:x}, {:x}", d[0], d[1]);
}
The output I am getting is:
1, 12
The tag field value is 1 (ie, Green) and the data field value is hex 12.
Exercise: Write similar programs to find out the memory layout of product types: tuples and structures.
Conclusion
All the basic Rust data types have a simple representation in memory; the common theme is to allocate everything on the stack without any layers of indirection. The only exception is when you need data structures which grow dynamically; in this case, the dynamic part is allocated on the heap and the stack allocated part will have a pointer to this heap allocated area plus some other information (like length, capacity etc).
When a data structure is passed to a function, you have two options: either copy the stack allocated part to the function or to pass a simple pointer to the beginning of the stack allocated part.
Experiment more with Rust and have fun!